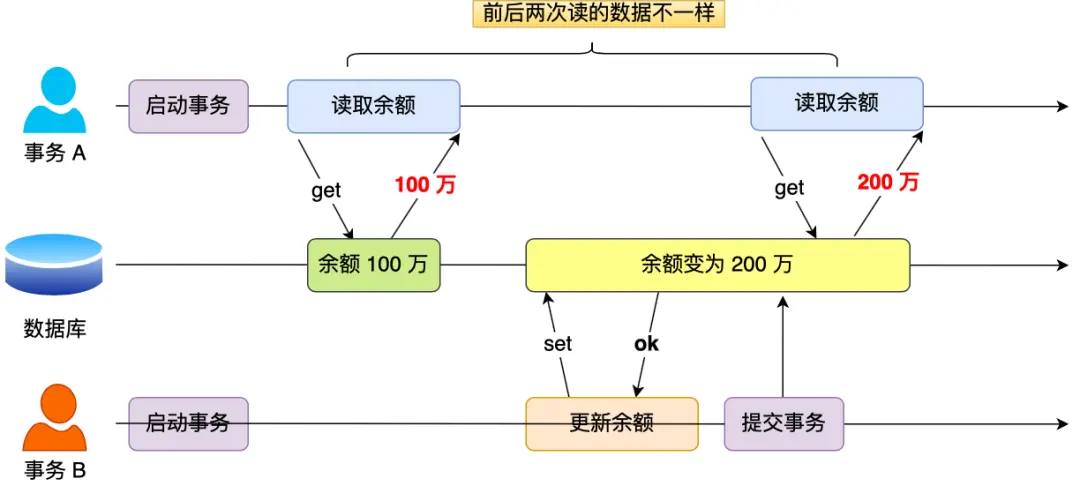
端到端无人驾驶:SparseDrive
论文精读
Abstract
完善的模块化自动驾驶系统被解耦为不同的独立任务,例如感知、预测和规划,遭受模块间信息丢失和错误累积的困扰。相比之下,端到端范式将多任务统一到一个完全可微的框架中。尽管端到端范式具有巨大的潜力,但现有方法的性能和效率都不令人满意,特别是在规划安全性方面。我们将此归因于计算成本高昂的BEV(鸟瞰图)特征以及预测和规划的直接设计。
为此,我们探讨了稀疏表示,并回顾了端到端自动驾驶的任务设计,提出了一个名为SparseDrive的新范式。具体来说,SparseDrive由对称稀疏感知模块和并行运动规划器组成。稀疏感知模块将检测、跟踪和在线映射以对称模型架构统一起来,学习驾驶场景的完全稀疏表示。对于运动预测和运动规划,我们回顾了这两个任务之间的巨大相似性,从而导致运动规划器的并行设计。基于这种将规划建模为多模态问题的并行设计,我们提出了一种分层规划选择策略,该策略结合了碰撞感知重核模块,以选择合理安全的轨迹作为最终的规划输出。
凭借如此有效的设计,SparseDrive在所有任务的性能上都大大超过了以前的最先进水平,同时实现了更高的训练和推理效率。
1. Introduction
传统自动驾驶系统的特点是任务按顺序模块化。虽然在解释和错误跟踪方面具有优势,但不可避免地会导致信息丢失和跨连续模块的累积错误,从而限制了系统的最佳性能潜力。
最近,端到端驱动范式成为一个很有前途的研究方向。这种模式将所有任务集成到一个整体模型中,并可以朝着规划的最终追求进行优化。然而,现有的方法在性能和效率方面都不令人满意。一方面,以前的方法依赖于计算昂贵的BEV特征。另一方面,直接的预测和规划设计限制了模型的性能。我们在图1a中将以前的方法总结为以bev为中心的范式。
为了充分利用端到端范式的潜力,我们回顾了现有方法的任务设计,并认为运动预测和规划之间的三个主要相似之处被忽视如下:
- 在预测周围智能体和自我车辆的未来轨迹时,运动预测和规划应考虑道路主体之间的高阶双向交互[^1]。然而,以往的方法通常采用顺序设计进行运动预测和规划,忽略了自我车辆对周围agents的影响。
- 准确预测未来的轨迹需要语义信息来理解场景,需要几何信息来预测智能体的未来运动,这既适用于运动预测,也适用于规划。虽然这些信息是在上游感知任务中提取的,但在自我车辆中却被忽略了。
- 运动预测和规划都是具有固有不确定性的多模态问题,但以往的方法只能预测确定性轨迹进行规划。
传统的策略,即BEV。(b)稀疏中心范式。(c) (a)和(b)的表现和效率比较。 图1:各种端到端范例的比较。(a)传统的策略,即BEV。(b)稀疏中心范式。(c) (a)和(b)的表现和效率比较。")
为此,我们提出了SparseDrive,这是一个以稀疏为中心的范例,如图1b所示。具体来说,SparseDrive由对称稀疏感知模块和并行运动规划器组成。使用解耦实例特征和几何锚作为一个实例(动态道路代理或静态地图元素)的完整表示,对称稀疏感知将检测、跟踪和在线映射任务与对称模型架构统一起来,学习一个完全稀疏的场景表示。
在并行运动规划中,首先从自我实例初始化模块获得一个语义和几何感知的自我实例。利用稀疏的自我实例和周围智能体实例,同时进行运动预测和规划,得到所有道路智能体的多模态轨迹。为保证规划的合理性和安全性,采用融合碰撞感知重核模块的分层规划选择策略,从多模态轨迹建议中选择最终规划轨迹。
通过以上有效的设计,SparseDrive释放了端到端自动驾驶的巨大潜力,如图1c所示。在没有附加功能的情况下,我们的基本模型SparseDrive-B大大降低了平均L2误差19.4% (0.58m vs. 0.72m)和碰撞率71.4% (0.06% vs 0.21%)。与之前的SOTA(最先进的)方法UniAD[15]相比,我们的小型模型SparseDrive-S在所有任务中都取得了卓越的性能,训练速度提高了7.2倍(20小时比144小时),推理速度提高了5.0倍(9.0 FPS比1.8 FPS)。
我们的主要工作贡献总结如下:
- 我们探索了端到端自动驾驶的稀疏场景表示,并提出了一个以稀疏为中心的范式SparseDrive,该范式将多个任务与稀疏实例表示统一起来。
- 我们修正了运动预测和运动规划^2之间的相似性,相应地导致了运动规划器的并行设计。为了提高规划性能,我们进一步提出了一种包含冲突感知重核模块的分层规划选择策略。
- 在具有挑战性的nuScenes基准测试中,SparseDrive在所有指标(尤其是安全关键指标碰撞率)方面都超过了以前的SOTA方法,同时保持了更高的训练和推理效率。
2. 相关工作
2.1 Multi-view 3D Detection(多视图三维检测)
多视角三维检测是保证自动驾驶系统安全运行的前提。LSS利用深度估计将图像特征提升到3D空间,并将特征拼合到BEV平面。后续工作将lift-splat操作应用到三维探测领域,在精度和效率方面都有了显著提高。一些研究预先定义了一组BEV查询,并将其投影到透视图中进行特征采样。另一项研究消除了对密集BEV特征的依赖。PETR系列引入了三维位置编码和全局关注来隐式学习视图变换。Sparse4D系列在3D空间中设置显式锚点,将其投影到图像视图中,以迭代的方式聚合局部特征并细化锚点。
2.2 End-to-End Tracking(端到端跟踪)
多目标跟踪(MOT)方法大多采用检测跟踪(tracking-by-detection)方式,依赖于数据关联等后处理。这样的流程不能充分利用神经网络的能力。受[2]中的对象查询的启发,一些作研究引入了跟踪查询,以流方式对跟踪实例进行建模。motor提出了tracklet-aware标签分配,这迫使轨迹查询持续检测相同的目标,并且存在检测与关联之间的冲突。Sparse4Dv3证明临时传播的实例已经具有身份一致性,并通过简单的ID分配过程实现了SOTA跟踪性能。
2.3 Online Mapping(在线地图)
由于制作高清地图的成本高,而且需要耗费大量人力,因此提出了在线地图作为高清地图的替代方案。HDMapNet组BEV语义分割与后处理,以获得矢量化的地图实例。VectorMapNet利用两级自回归变压器进行在线地图构建。MapTR将映射元素建模为等价置换的点集,避免了映射元素定义的模糊性。BeMapNet采用分段贝塞尔曲线来描述地图元素的细节。streamapnet引入了BEV融合和查询传播来进行时态建模。
2.4 End-to-End Motion Prediction(端到端运动预测)
为了避免传统管道中的级联误差,提出了端到端运动预测方法。FaF使用单个卷积网络来预测当前和未来的边界框。internet更进一步,对高层次行为和长期轨迹进行了推理。PnPNet引入了一个在线跟踪模块来聚合运动预测的轨迹水平特征。
ViP3D采用代理查询进行跟踪和预测,以图像和高清地图为输入。PIP将人工标注的高清地图替换为局部矢量化地图。
3. Method

3.1 Overview
SparseDrive的总体框架如图2所示。具体来说,SparseDrive由图像编码器、对称稀疏感知和并行运动规划三部分组成。给定多视图图像,图像编码器首先将图像编码为多视图多尺度特征地图:
$$
I=\left{I_{s} \in \mathbb{R}^{N \times C \times H_{s} \times W_{s}} \mid 1 \leq s \leq S\right}
$$
其中s为尺度数,N为摄像机视图数。在对称稀疏感知模块中,将特征映射I聚合为两组实例,学习驾驶场景的稀疏表示。这两组实例,分别代表周围的agents和地图元素,被馈送到并行运动规划器中与初始化的自车交互。运动规划器同时预测周围agents和自我车辆的多模态轨迹,并通过分层规划选择策略选择安全轨迹作为最终规划结果。
3.2 Symmetric Sparse Perception(对称稀疏感知)

如图3所示,稀疏感知模块的模型结构呈现出结构对称性,将检测、跟踪和在线映射统一在一起。
3.2.1 稀疏检测
稀疏检测:周围agents由一组实例特征$F_{d} \in \mathbb{R}^{N_{d} \times C}$和锚框$B_{d} \in \mathbb{R}^{N_{d} \times 11}$表示,其中Nd是锚点的数量,C是特征信道维度。每个锚框都有位置、尺寸、偏航角和速度的格式:
$$
{x, y, z, \ln w, \ln h, \ln l, \sin y a w, \cos y a w, v x, v y, v z}.
$$
稀疏检测分支由$N_{d e c}$个解码器组成,包括一个非时间解码器和$N_{d e c}-1$个时间解码器。每个解码器将特征图(feature map)I、实例特征(instance feature)Fd和锚框Bd作为输入,输出更新的实例特征和改进的锚框。非时间解码器以随机初始化的实例作为输入,而时间解码器的输入来自当前帧和历史帧。
具体来说,非时间解码器包括三个子模块:可变形聚合、前馈网络(FFN)和用于细化(调整锚库框)和分类的输出层。可变形聚合模块在锚框Bd周围生成固定或可学习的关键点,并将其投影到特征图I中以进行特征采样。实例特征Fd通过与采样特征求和来更新,并负责预测分类得分和输出层中锚框的偏移。
时间解码器有两个额外的多头注意层:上一帧和当前实例的时间实例之间的时间交叉attention,以及当前实例之间的self attention。在多头注意层中,锚箱被转化为高维锚嵌入$E_{d} \in \mathbb{R}^{N_{d} \times C}$,并用作位置编码。
3.2.2 稀疏的在线地图
在线映射分支与检测分支共享相同的模型结构,但实例定义不同。对于静态地图元素,锚点被表示为具有Np个点的折线:
$$
\left{x_{0}, y_{0}, x_{1}, y_{1}, \ldots, x_{N_{p}-1}, y_{N_{p}-1}\right}
$$
然后,所有地图元素都可以用地图实例特征$F_{m} \in \mathbb{R}^{N_{m} \times C}$和锚折线$L_{m} \in \mathbb{R}^{N_{m} \times N_{p} \times 2}$,其中Nm是锚折线的数量。
3.2.3 稀疏跟踪
对于跟踪,我们遵循Sparse4Dv3的ID分配过程:一旦实例的检测置信度超过阈值Tthresh,它就会被锁定到目标上并分配一个ID,该ID在整个时间传播过程中保持不变。这种跟踪策略不需要任何跟踪约束,从而为稀疏感知模块提供了一种优雅而简单的对称设计。
3.3 Parallel Motion Planner(运动规划器)

对于自车锚点,位置、尺寸和偏航角可以直接设置,因为我们知道自我车辆的这些信息。对于速度,直接从地面真实速度初始化会导致自我状态泄漏^3,如[27]所示。因此,我们增加了一个辅助任务来解码当前的自我状态EST,包括速度、加速度、角速度和转向角。在每一帧,我们使用上一帧的预测速度作为自我锚定速度的初始化。
3.3.1 Spatial-Temporal Interactions(时空相互作用)
为了考虑所有道路代理之间的高级交互,我们将ego实例与周围的agents连接起来,得到agent级实例:
$$
F_{a}=\operatorname{Concat}\left(F_{d}, F_{e}\right), B_{a}=\operatorname{Concat}\left(B_{d}, B_{e}\right)
$$
由于自车是在没有时间线索的情况下初始化的,这对规划很重要,我们设计了一个大小为(Nd+1)×H的实例内存队列用于时间建模,H是存储的帧数。然后进行三种类型的交互来聚合时空上下文:agent-temporal cross-attention, agent-agent self-attention and agent-map cross-attention。
请注意,在稀疏感知模块的时间交叉注意中,当前帧的所有实例与所有时间帧的所有实例相互作用,我们称之为场景级交互。而对于这里的agent-temporal cross-attention,我们采用实例级交互,使每个实例都专注于自身的历史信息。
然后,我们预测了多模态轨迹$\tau_{m} \in \mathbb{R}^{N_{d} \times \mathcal{K}{m} \times T{m} \times 2}$,$\tau_{p} \in \mathbb{R}^{N_{c} \times \mathcal{K}{p} \times T{p} \times 2}$并为周围主体和自我车辆打分:$s_{m} \in \mathbb{R}^{N_{d} \times \mathcal{K}{m}}$,$s{p} \in \mathbb{R}^{N_{c m d} \times \mathcal{K}_{p}}$,Km和Kp是运动预测和规划的模式数量,Tm和Tp是运动预测和规划的未来时间戳数量,Ncmd是规划的驾驶命令数量。
3.3.2 分层规划选择
现在我们有了多模态规划轨迹建议,为了选择一个安全的轨迹$\tau_{p}^{*}$来遵循,我们设计了一个分层规划选择策略。首先,我们选择一个子集的轨迹建议$\tau_{p, c m d} \in \mathcal{K}{p} \times T{p} \times 2$,对应于高级命令cmd。然后,采用了一种新颖的碰撞感知重排序模块来确保安全。根据运动预测结果,我们可以评估每个规划轨迹提案的碰撞风险,对于碰撞概率较高的轨迹,我们降低了该轨迹的得分。在实践中,我们简单地将碰撞轨迹的分数设置为0。最后,我们选择得分最高的轨迹作为最终的规划输出。
3.4 End-to-End Learning
3.4.1 Multi-stage Training
多阶段培训。SparseDrive的训练分为两个阶段。
在第一阶段,我们从头开始训练对称稀疏感知模块来学习稀疏场景表示。
在阶段2中,稀疏感知模块和并行运动规划器在没有模型权重冻结的情况下一起训练,充分享受了端到端优化的好处。更多培训细节见附录B.4。
3.4.2 Loss Functions
损失函数包括四个任务的损失,每个任务的损失可以进一步分为分类损失和回归损失。对于多模态运动预测和规划任务,我们采用赢家通吃策略。对于规划,自我状态会有额外的回归损失。我们还引入了深度估计作为辅助任务,以提高感知模块的训练稳定性。端到端培训的总体损失函数为:
$$
\mathcal{L}=\mathcal{L}{\text {det }}+\mathcal{L}{\text {map }}+\mathcal{L}{\text {motion }}+\mathcal{L}{\text {plan }}+\mathcal{L}_{\text {depth }}
$$
附录B.3中提供了有关损失函数的更多详细信息。
在计算完成后,我们将得到的坐标进行可视化处理,我们将三维视图转换为俯视图,并将物体中心投影在二维平面上,投影的结果如图3.3所示。
图3.3物体中心可视化
上图中,原点坐标(0,0)周围是白色的,这是因为我们以自车中心为原点建立坐标系,所以原点周围是自车的投影,不属于周围物体。同时,我们发现
$$
\begin{aligned}\\text{Planning L2} = \frac{1}{T} \sum_{t=1}^{T} \sqrt{(x_t^{\text{pred}} - x_t^{\text{gt}})^2 + (y_t^{\text{pred}} - y_t^{\text{gt}})^2}\\end{aligned}
$$

[^1]: 高阶交互(higher-order interactions):指的是多个交通参与者之间的复杂相互影响,而不仅仅是考虑直接的单一影响。例如,某辆车的行驶决策可能不仅受前车的影响,还可能受到侧面或后方其他交通参与者的影响。
双向交互(bidirectional interactions):强调不仅仅要考虑自动驾驶车辆与其他交通参与者的交互,还要考虑其他交通参与者如何感知并反应自动驾驶车辆的行为。即,自动驾驶车辆与周围交通参与者之间的互动是相互的、动态的,而非单向的。
运动规划则是自动驾驶系统的决策部分,主要目的是根据当前的环境和目标,决定自动驾驶车辆的最优运动路径。
 微信
微信 支付宝
支付宝